Over the years I have gotten know several of the folks working at the Florida Department of Transportation District 7 here in Tampa. Ideally I wanted to work with FDOT as my internship. Unfortunately budget concerns precluded the department from offering a formal internship opportunity. However, the window of opportunity did not fully close with District 7, as thanks to research efforts from my brother in Survey and Mapping, it turns out FDOT does have a formal Volunteer Program.
The objectives of the Volunteer Program "is to enhance the delivery of quality services by promoting community involvement in the Department of Transportation, while providing volunteers with a chance to contribute their valuable time and talents." Compensation was not my goal for an internship, instead I sought the opportunity to further enhance and expand my GIS skillset. While there were some paperwork issues to address and HR related aspects to iron out, I was approved for the Volunteer Program on August 26!
With my cartography background spanning two decades, I will be provided the opportunity to help out multiple departments at FDOT. Some of my duties outlined for the GIS Volunteer program include learning how to create map services, web maps and web applications, reviewing and providing recommendations for symbology settings for GIS layers, and helping draft a training manual for making maps in ArcGIS Pro according to D7 specifications. I will also get to work with the Survey and Mapping department.
This Fall I also registered to attend the GeoFlo Summit, which takes place on November 14, 2024 in Plant City. This will be the second time I have attended the meeting of GIS Users, but first time as an active GIS User! One of the sponsors of the event is the Tampa Bay GIS Users Group (TBGIS). TBGIS regularly hosts Networking Socials, and the next one takes place this evening in Seminole Heights, Tampa. There is no formal membership to TBGIS and everyone in the GIS community and anyone curious about the geospatial world is welcomed to join any of their events. Social media connections and where to join the TBGIS mailing list is at TBGIS Updates.
Thanks to my work with GISCAPS, I was able to attend the ESRI User Conference in San Diego back in 2014. I also attended the FDOT Symposium in 2019. Those were large-scale events, but the premise was the same, being able to meet with and interact with others in the GIS industry. I chose to focus on TBGIS because they are local and offer in-person events.







")
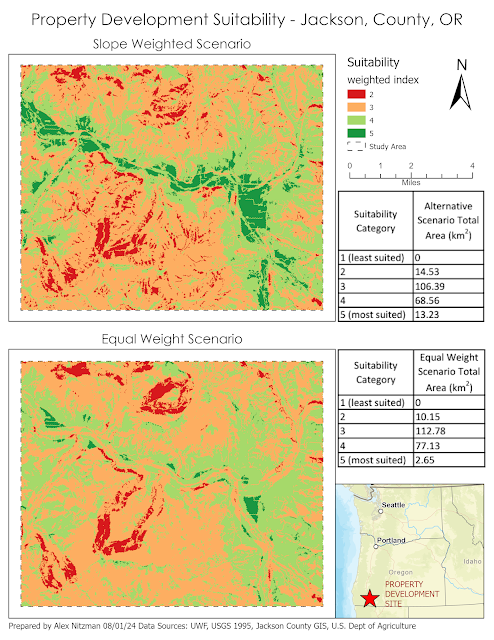
 The final scenario for the lab of GIS Applications Module 6 is to determine a potential protected corridor linking two areas of black bear habitat in Arizona's Coronado National Forest. Data provided included the extent of the two existing areas of known black bear habitat, a DEM, a raster of land cover and a feature class of roads in the study area. Parameters required for a protected corridor facilitating the safe transit of black bear included land use away from population and preferably with vegetation, mid level elevations and distances far from roadways.
The final scenario for the lab of GIS Applications Module 6 is to determine a potential protected corridor linking two areas of black bear habitat in Arizona's Coronado National Forest. Data provided included the extent of the two existing areas of known black bear habitat, a DEM, a raster of land cover and a feature class of roads in the study area. Parameters required for a protected corridor facilitating the safe transit of black bear included land use away from population and preferably with vegetation, mid level elevations and distances far from roadways.